ビールに学ぶ診断士試験 ー マーケットバスケット分析 by ひろし

☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆

まいど、どーも!
14代目の大阪弁担当こと、ひろしです。
蒸し暑い季節になってまいりました。寝苦しい夜が続き、エアコンのお世話にばっかりなっております。試験まであと5週間、Takeshi![]() の記事にもありましたが、体調管理にはお気をつけください。
の記事にもありましたが、体調管理にはお気をつけください。
本日は、こんな蒸し暑い時期に飲みたくなる、キーンと冷えたビールのお話です。
某所ビアガーデンにて
ぷはー


ビールが美味しい季節になりましたね
ビアガーデンもええけど、ベランダで缶ビールってのもええよね。
帰りにスーパーでおつまみと一緒に買うていこ。
スーパーでビールって、言うたら「ビールと紙おむつが一緒によく売れる」って話がありますよね
兄ちゃん、紙おむつをツマミにしてビール飲むん?
やめとき、お腹こわすで。

食わんわ!
ビールとオムツの関係
「ビールと紙おむつが同時に購入される」
マーケティングやデータ分析の教科書でよく紹介されるエピソードです。
1990年代前半のアメリカで、コンサル会社が大手スーパーマーケットの販売データを調べたところ、「顧客がビールと紙おむつを一緒に購入する傾向がある」という事象を発見した、というお話です。
意外な商品同士の同時購買ですが、その背景には「アメリカのスーパーマーケットで、かさばる紙おむつを買いに来た父親が、一緒に自分のための缶ビールを買っていくから」という理由があるといわれています。
本日はこのエピソードを起点に、運営管理と経営情報システムの二つの科目についてお話ししようと思います。
(1992年12月のウォールストリートジャーナル、”Supercomputers manage holiday stock”という記事に取り上げられたのが出典のようです。原著にあたれておりませんので参考情報とさせてください。)
マーケットバスケット分析(運営管理)
さて、先ほどのエピソードで「ビールと紙おむつ」という二つの商品が一緒によく売れる例を出しましたが、このように商品購買の関連性を探る分析をマーケットバスケット分析と言います。
マーケットバスケット分析では支持度、信頼度、期待信頼度、リフト値などの数値を求めて、分析していきます。ここでは、各数値の定義とともに実際の数字をで計算しながら覚えましょう。
ここではホップの香りが自慢の![]() ベストビールとおつまみにもピッタリ
ベストビールとおつまみにもピッタリ トロオドンスナック
トロオドンスナック
に登場してもらいましょう。ここでは近所のスーパー アストロマートの1日の客数をもとに、ベストビールがトロオドンスナックの購入にどう関連しているか、見てみましょう。
アストロマートの1日の客数をもとに、ベストビールがトロオドンスナックの購入にどう関連しているか、見てみましょう。
そのレシートを分析したものが以下の表です。
| 購入したもの | 購入したお客さんの数 |
|---|---|
| 500人 | |
| 125人 | |
| を購入した客数 | 80人 |
| の両方を購入した客数 | 50人 |
図にまとめるとこんな感じになります。(このような関係性を表す図をベン図といいます。)

ここから、マーケットバスケット分析に使う数値をそれぞれ求めていきます。
支持度
すべての顧客のうち、商品Aと商品Bを同時に購入する客数の割合です。計算式は以下のとおりです。
支持度 = 同時購入者数 / 購入者全体数
この例では、お客さん全体が500人、ベストビールとトロオドンスナックの両方を購入したお客さんは50人なので、
支持度 = 50人 ÷ 500人 = 0.1
となります。

信頼度
商品Aを購入した顧客のうち、商品Bを同時に購入した客数の割合です。計算式は以下となります。
信頼度 = AとBの同時購入者数 / 商品Aの購入者数
一方で、期待信頼度という数値もあります。
期待信頼度 = Bの顧客数 ÷ 全体顧客数
これは全顧客の中でBを購入した客数の割合、いわゆるB単独の人気を表します。
ここでは、ベストビールがトロオドンスナックに与えた影響を見るので、同時購入者50人とベストビール購入者125人との割合を計算して
信頼度 = 50人 ÷ 125人 = 0.4
また、トロオドンスナックを買った人は80人なので、トロオドンスナックの期待信頼度は
期待信頼度 = 80人 ÷ 500人 = 0.16
となります。

リフト値
リフト値とは期待信頼度に対する信頼度の割合です。つまり、「商品Bを単独購入する割合」と「商品A購入者のうち商品Bを購入する割合」を比較したものとなります。
リフト値は下記の計算式で求められます。
リフト値=信頼度/ 期待信頼度
このリフト値が高いほど、「商品Bは商品Aと同時に購入されやすい」と言えます。リフト値は1以上となったとき、「同時購入が、起こりやすい」と判断する指標になります。
上の例をもとに計算すると、
リフト値 = 0.4 ÷ 0.16 = 2.5
となり、ベストビールとトロオドンスナックを同時購入する人はスナック単独で購入する人よりも2.5倍の割合で多い、ということができます。

ここでは1組の商品同士しか計算しませんでしたが、これらの数値を各商品の組み合わせごとに計算し、比較することで同時購入の傾向を知ることができます。
これらの結果は商品陳列や価格設定に応用されることになります。
過去問ではこれらの数字を計算させる問題が多く出題されています。公式を覚えて、数値を計算できるようにしておきましょう。
出題実績の例
【マーケットバスケット分析】
- 令和4年 第39問(設問1,2):上記の指標を計算させる問題が出題
- 平成30年 第39問(設問1,2):上記の指標の定義について出題
- 平成29年 第40問(設問1,2):上記の指標の定義と計算問題が出題
- 平成28年 第39問(設問1,2):上記指標の計算について出題
*ちなみに、間が抜けている令和元年~3年はRFM分析(Recency:直近購買日、Frequency:購入頻度、Monetary:購入金額の3つの観点から分析する手法)が出題されていました。こちらも重要項目です。
データマイニング(経営情報システム)
先ほどは運営管理の一テーマとしてマーケットバスケット分析について説明しましたが、マーケットバスケット分析は、経営情報システムで出題されるデータマイニングの手法のひとつとして分類されます。
データマイニングとはどんなものか、簡単に見ていきましょう。
データマイニングとは
データマイニングとは、大量のデータに対して統計学やAIなどを用いて分析を行い、何らかの知見を得ることです。
もともと、マイニング(mining)とは鉱山を掘ることをいいます。ビッグデータと呼ばれる非常に膨大な鉱山の中で、金脈のような有益な情報を探し出すことから、この名がついています。
ビールと紙おむつのエピソードの出典と言われる「”Supercomputers manage holiday stock”(スーパーコンピューターがホリデーシーズンの在庫を管理する)」とあるように、データマイニング、あるいはそれを研究するデータサイエンスはコンピューターの発展によって、飛躍的に研究が進み、普及してきました。
話は少しそれますが、データサイエンスで使われる「比ゆ的な名称」はデータマイニング以外にもいくつかあります。
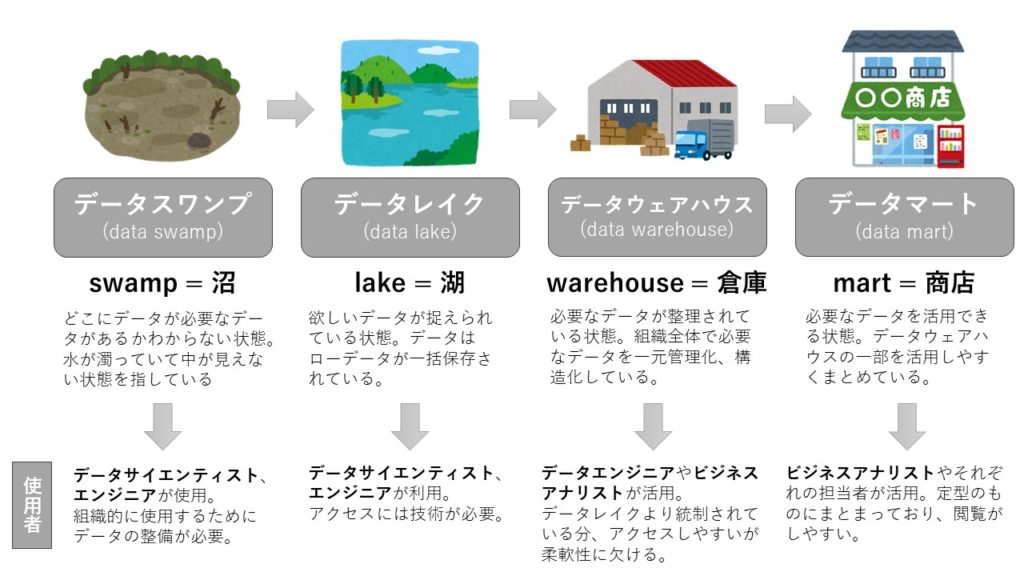
データスワンプ、データレイク、データウェアハウス、データマートが例として挙げられます。これらは全てデータの格納庫を意味しますが、それぞれデータの整理・管理されている度合いが違います。結果的にユーザーも異なってきます。
それを語源と一緒に覚えてしまいましょう。どの程度データが整理されているかが理解しやすくなります。

ちょっと、僕のネタ取らないでよ
データマイニングの手法
データマイニングの手法には様々なものがあります。これらは様々な分野で活用されていますが、マーケティング分野でも広く使われています。代表的なものをいくつか見てみましょう。
アソシエーション分析
データの中からパターンや関連性を抽出する手法。「もしこうだったら(前提)、こうなるだろう(結果)」といった前提と結果を仮定したうえで、データ同士の関連性を分析する。
アソシエーション分析は、「こうだったら、こうなる」の法則性(アソシエーションルールと呼びます)をしらみつぶしに探し、その前提と結果の関係性が強いパターンを割り出します。「この単語を検索した人はこの単語も検索する」といった検索キーワード分析などがあります。また、先述した「Aを購入した人はBも購入する」という法則を調べるマーケット・バスケット分析もアソシエーション分析の代表例となります。
クラスター分析
異なる性質が混ざり合う集団の中から、似たもの同士を集めクラスター(集落)を作り、対象を分類する手法。
アンケートの結果などから顧客のセグメンテーションを行ったり、多くの商品を似たようなカテゴリに分けたりするのに用いられます。性別や年齢など明確に分かれる属性情報だけでなく、「イメージ」や「価値観」など、はっきりと分類しにくい指標も分類することができるのが特徴です。
「収集・分析した顧客情報を元に類似した顧客のグループに対してDMを配信する」など、より効果的・効率的なマーケティングを行うために活用されます。
ロジスティック回帰分析
複数の要因から、物事の発生確率を予測する手法。
回帰分析とは「要因と結果の因果関係を関数(数式)の形であらわす統計手法」を指します。要因を指すもの、結果を指すもの、それぞれを数値化したものを「説明変数」「目的変数」と呼び、説明変数の個数や関係式によってそれぞれ呼び名があります。
たとえば、説明変数が一つのものを単回帰分析、複数のものを重回帰分析と言います。
財務・会計の固定費・変動費分解は製品の製造量(=説明変数)と費用(=目的変数)の関係から数式を求める単回帰分析の例です。
費用(=目的変数)を求めるために、製造量(=説明変数1)以外に製品の保管期間(=説明変数2)や為替変動(=説明変数3)など、複数の要因がはいってくると、重回帰分析となります。
その回帰分析の中でも、ロジスティック回帰分析は、目的変数が0~1の間しかとらないという特殊な関数を使って行います。ここから、複数の説明変数を用いたときの発生確率を求めるのに使われます。(説明変数は1つの場合、複数の場合、共にあります。)
例えば、「割引クーポンの割引額から購入確率を求める」、「年齢、性別、職業からメールの開封率を求める」などの活用例があります。
データマイニングに関連する分析方法や統計解析の手法(さたっち はt検定を紹介してくれましたね。)はきちんと勉強しようとすると非常に難しいです。
はt検定を紹介してくれましたね。)はきちんと勉強しようとすると非常に難しいです。
細かいことを覚えるには非常に時間がかかるので、苦手な方は「どんな時にどの分析を使うのか」をざっくり覚えていただければと思います。
出題実績の例
【データ支援システムに関する問題】
- 令和4年 第4問:データレイクの定義について出題
- 令和3年 第8問:データ管理に関する言葉の定義について出題
- 令和元年 第16問:データ支援システムに関する言葉の定義について出題
【データマイニングの分析手法に関する問題】
- 令和2年 第24問:分析手法の説明について出題
- 平成29年 第24問:多変量解析に関することばについて出題
なるほど、なるほど
なんや、けったいなモン食べると思ったら。ちゃうんやな。


そもそも食いモンちゃうやろ
受験生の皆さんも変なモン食べてお腹こわさんようにー

試験まであと少し。
お身体には気を付けて~
ほなね~♪
祝杯あげるの待ってるで~
明日はアストロ がお話してくれます。よろしく!!
がお話してくれます。よろしく!!
☆☆☆☆☆
いいね!と思っていただけたらぜひ投票(クリック)をお願いします!
ブログを読んでいるみなさんが合格しますように。
にほんブログ村
にほんブログ村のランキングに参加しています。
(クリックしても個人が特定されることはありません)

