【渾身】【経営情報システム】サルでもわかる? RDBの正規化
こんにちは、今日も元気にKKD、手相観診断士のかおりんです。
今日は、春セミナーにお越し頂いた受講生の方とお約束を果たすべく、リレーショナルデータベース(略してRDB)について・・・。「データベースの正規化」の解説の記事です。ゆるわだしか書かないと思っていた私が、まさか渾身を書く日がくるなんて。
ちなみに、本記事はあくまでかおりんの理解の範疇なので、ざっくりした解説の部分もあります。
「何となく正規化がイメージができて、問題が解けるようになる」ことがゴールなので、細かいツッコミはなしでお願いします。

そもそも、何でデータベースを「正規化」するの?
ずばり、データを扱いやすくするため。
起票された帳票をシステムで扱えるようにするには、帳票をレコードといわれる1行の情報(データ)に変換します。
ただ、レコードは同じような情報が繰り返されていたりして、人が一見しただけではなんのことだかわかりにくい。
下の例でも、「表」の形は横に長くて見づらいですよね。この形では、整理したり、更新したり、分析するのに使いにくい。
データを整理して使いやすくすることが正規化の目的です。
ほな、例題で帳票を正規化してみよう。
<例題>今日は7代目の女性メンバーで女子会。みんなが注文したドリンクは下記の通り。(クリックで拡大できます) ※フィクションです

盛り上がったため、6回も注文しています。注文ごとに伝票が起票されています。
Q1)上記の注文履歴(伝票)を表にしてみよう。
A1)下記の表の通り。(クリックで拡大できます)
![]()
伝票1枚を1レコードとしてデータにしています。この状態の表を非正規形といいます。
表を作るポイントは、Ⅰ.1レコード(=1行)に、データは1つ(=例題では伝票1枚が1データ)Ⅱ.表の1行を特定できる項目(キー列)を考える、の2点。
また、この表の中で『1・2・3・4』と番号がついている列が、同じ種類の情報が繰り返し書かれている部分(=冗長な部分)です。では、これをふまえて
Q2)上記の表を第一正規化すると、どうなるか。
A2)下記の表の通り。(クリックで拡大できます)

第一正規化によって、繰り返しの部分を分離します。
表を『注文票』と『注文明細』に分けました。表で同じ種類の情報が繰り返し書かれている部分(=冗長な部分)「商品コード・商品名・・・」などの項目は、冗長性が排除され(=繰り返しをなくして)注文明細で各項目1列ずつにまとまっています。
Q3)上記を第二正規化すると、どうなるか。
A3)下記の表の通り。(クリックで拡大できます)
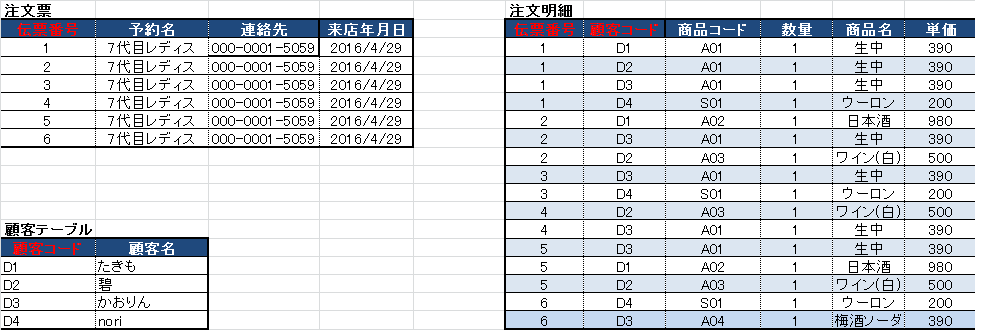
第二正規化では、主キーに関わる情報を別のテーブルに分離します。
今回のケースだと、伝票番号のほかに「顧客コード」が主キーです。そこで、顧客コードに完全にひもづく顧客名に注目し、「顧客コード」と「顧客名」をテーブルにして注文明細から分離します。
主キーというのは「これがきまると、データを特定できる」項目のこと。
このデータの主キーは「伝票番号」と「顧客コード」です。
たとえば、お店の人におかわりを頼むのに
「1回目の注文で頼んだドリンクください」と言っても、何のドリンクか特定できません。生中なのか、ウーロン茶なのかわからず、お店の人は困ってしまいます。しかし、「1回目の注文で、かおりんが頼んだドリンクください」と言うと、生中と特定できるのでおかわりが頂けます。
何回目の(=伝票番号)と、誰が(=顧客コード)でドリンク(=レコード)を特定できる、というイメージです。(ドリンク=レコードという表現は厳密には正確ではないかもしれませんが、イメージで)
また、この「第二正規化」によって表のメンテナンスが容易になります。例えば、かおりん→ごぶりんのように名前が変わるなど、顧客の情報に変化があった場合でも、注文明細の該当レコード全てを修正するのではなく、顧客テーブルだけを修正すればOKです。
Q4)上記を第三正規化すると、どうなるか。
A4)下記の表の通り。(クリックで拡大できます)
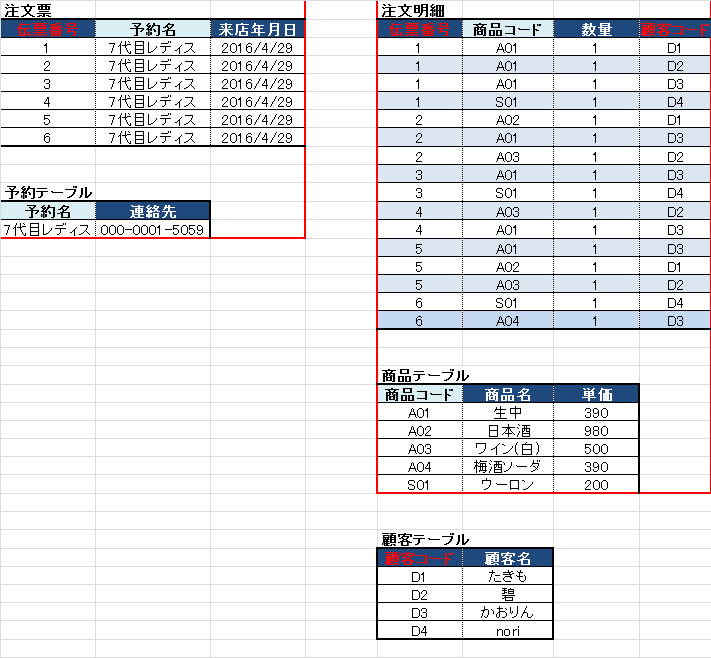
第三正規化では、主キー以外で従属関係にある項目を別テーブルとして分離します。
例えば、注文票の中にある「予約名」と「連絡先」は、予約名が決まれば自動的に連絡先も決まるので”従属関係”です。(関数従属)
予約名を「外部キー」(=外に分離した表とつなぐ項目)として、予約テーブルを分離します。
同様に、「商品コード」に対して、「商品名」「単価」は関数従属ですので、商品テーブルとして分離できます。
第三正規形で分離する項目は、どうやら「推移従属関係にある項目」っていうみたいです。・・・が、「推移従属関係」の理解とか・・・そこまでコアな知識は・・・正直いらんのんちゃうかな・・・?と思います。詳しく知りたい方は、文末に記載した参考記事を見てください。
このように、細かくテーブルを分離する=情報を整理すると、メリットが3つあります。
1)データのメンテナンスがしやすくなります。
例えば、生中の値段が390円から490円に値上げした!という時には商品テーブルの1か所のみ修正すればOK。正規化していないと、注文明細を1レコードずつ修正しなくてはいけません。
2)データを小さくできます。
非正規形の1レコードに比べて、正規化されたデータでは1レコードが短くなります。そのため、データ自体の大きさを小さくすることができます。データ処理の効率も、やり方を間違えなければUPするはず。
3)データの共有化が楽になります。
正規化されたデータは他のデータベースでも流用しやすく、データ移行時の負担も軽減できます。実際の運用ではこのメリットは結構大きいと思います、個人的には。
超ざっくりイメージで、正規化のまとめ。
非正規形でも、1レコードには1つの情報で。主キーと外部キーを意識。
第一正規形は「繰り返しをなくす」
第二正規形は「主キーに関わる情報を別テーブルに分離」
第三正規形は「主キー以外に関わる情報で、別テーブルに分離できるものを分離」
正規化についての出題は、直近ではH27過去問の第7問にあります。
※超ザックリの記事なので、特に今日の記事は「最初のイメージ作り」にご活用くださいね。きちんとした理解はぜひ各自の学習で深めてください。
参考記事:
【DB概論】正規化の手順:@IT記事より
データの正規化
【情報】正規化なんて怖くない
今日も診断士を目指すみなさまに、幸あれ☆
ほな!
かおりん
