【情報】機械学習 総まとめ! by AZUKI

☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
一発合格道場ブログを
あなたのPC・スマホの
「お気に入り」「ブックマーク」に
ご登録ください!
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
はじめに
こんにちは、AZUKIです。
1次試験まで、残り2週間となりました。最後の総仕上げとして、過去問を鬼のように皿回ししている時期かと思います。
さて、以前略語記事で、ここ最近連続で出ている略語について解説しました。
しかし、略語以外でもう1つ超頻出論点があります。
それは、機械学習です。なんと令和2年度 ~ 令和5年度 沖縄再試験にかけて5回連続で出題されています。
機械学習というと何やらハードルが高いイメージがありますが、診断士試験で問われる部分は複雑な計算もアルゴリズムも必要なく、用語とその意味を覚えるだけで済みます。
早速、解説に参りましょう!
AZUKI、”暗記”じゃなくて”理解”できる記事を書いてや!


な、なるべくわかりやすい解説になるように頑張ります・・・(自己紹介記事でイキったこと書かなきゃよかった・・・)
(リアルせーでんきは別にプレッシャーをかけてこないのですが、僕の心の中のリトルせーでんきが毎回プレッシャーをかけてくるのです・・・)
機械学習とは
機械学習とは、文字通り機械(コンピューター)がデータを使って学習し、性能が改善されることを指します。
人間が経験から学び、知恵を得るのと同じですね。
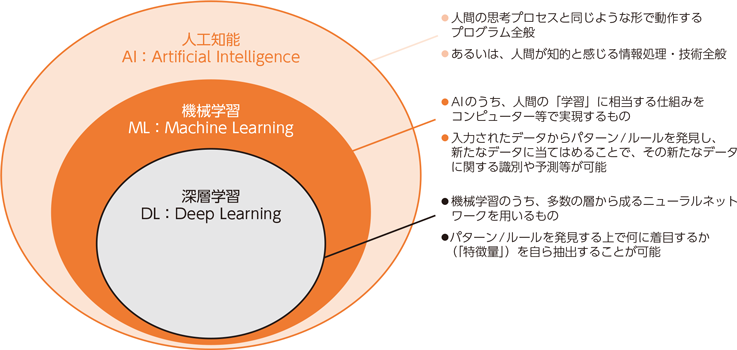
昨今では、AI(人工知能)とセットでよく聞く言葉になっていますが、あくまで機械学習はAIを実現するための手法の1つです。
他にAIを実現するために使われる手法として、特定の手順に従って問題解決をさせるルールベース型AIや、データから条件に一致した値を見つける探索アルゴリズムが存在しています。
ルールベース型や、探索アルゴリズムの例として、下記のようなパソコン修理受付のチャットボットがあります。
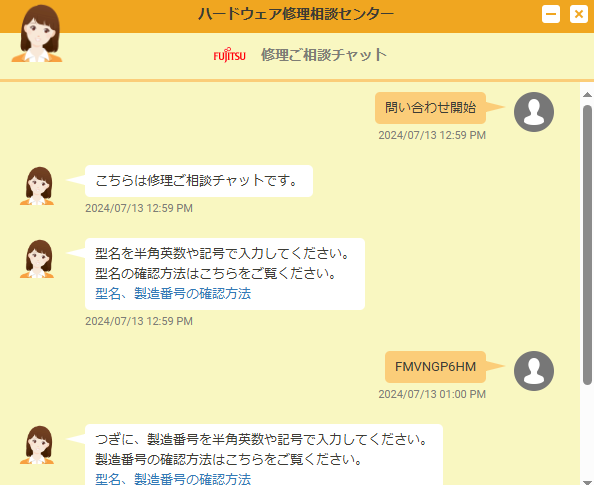
最初に「問い合わせ開始」という定型文が入力されたら、「こちらは修理ご相談チャットです」という文章と、型名を入力させる文章を返信するというルールになっていると思われます。
次に型名を入力すると、該当する型名があるかを探索します。探索した結果、該当する型名が見つかったので製造番号を入力させる文章を返信してきます。もし、ルールに違反したり、探索結果が見つからないとそっけない返事が返ってきます。
これに対して、機械学習の一例として、皆さんご存じChatGPTに同じ内容で問い合わせてみましょう。
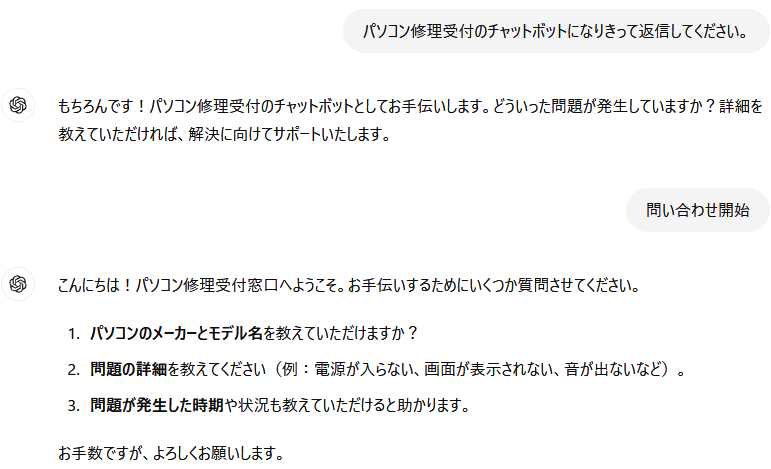

僕の口説き文句は華麗に受け流されましたが、こちらの文章に対して自然な日本語で返してくれていますね。もちろん、ChatGPTにパソコンの修理受付の機能はありません。
ChatGPTは、インターネット上の膨大な文章から言葉を学び、生成した文章に対して人間が「良い・悪い」のフィードバックをすることで、文章の良し悪しを学習します。

AIと機械学習の関係性はなんとなく分かりましたか? 次は、機械学習において大切な概念を紹介します!
特徴量について
機械学習の理解において必須と言える概念があります。それは特徴量という概念です。
例えば、僕たちは普段「イヌ」と「ネコ」を当たり前のように見分けられていますが、なぜ見分けられているのでしょうか?
イヌであれば「丸くて大きな黒目」「垂れ下がった耳」「ボリュームのある体毛」、ネコであれば「額が広く丸い顔」「口の周りの長いヒゲ」「尖った三角形の耳」などの特徴で見分けていると思います。
これらの特徴は、人間であれば文章で表せますが、コンピューターには数値で与えてやらなければなりません。このように、対象のデータの特徴を数値化したものを特徴量といいます。
特徴量は、出力データ(「イヌ」「ネコ」などの結果)であるラベルを予測するために使われます。
特徴量の計算方法については、ベクトル・行列など数学の知識が必要で、診断士試験には関係がないので割愛します。(というか、僕もニワカすぎて計算方法までわかりません・・・)
いやいやネコちゃんはそれだけじゃなくて、あのちっちゃくて愛らしい足や、柔らかいお腹が・・・


ジ、ジジにゃんとテトにゃんの話は後で聞くから! 次からは、いよいよ機械学習の手法を説明します!
教師あり学習
教師あり学習とは、初めから正解(教師)を与えたデータを扱って学習させる手法です。
正解のあるデータを使って学習するため、正解や不正解が明確な問題解決に向いており、例えば迷惑メールのフィルタリングや、選挙候補者の得票率予測などに使われています。
例えば、大量の動物の画像にあらかじめイヌ、ネコ、ウサギ・・・とラベリングします。これらを正解(教師)データとして学習を行うことで、学習していない画像を読み込ませてもどの動物かを判定することができます。
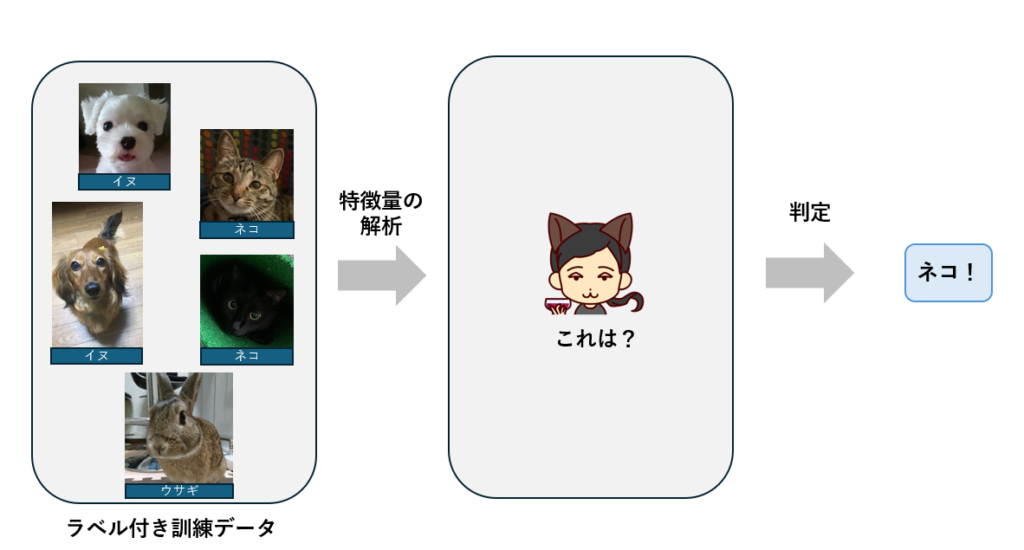
教師あり学習には、分類と回帰という2つの予測方法があります。
- 分類:分析するデータがどのクラスに所属するかを予測します。例としては、上記の動物の種類の判定があります。
- 回帰:連続したデータから未来を予測することです。例としては、天気予報や需要予測があります。
また、回帰には、線形回帰やロジスティック回帰など手法が分かれています。
この2つの違いを理解するために、日経平均株価の予測を例として考えてみましょう。
下記はここ1年の日経平均株価のグラフです。青線は証券会社が集計した実際の値動きのグラフであり、赤線は僕が適当に引いた株価トレンドのグラフです。
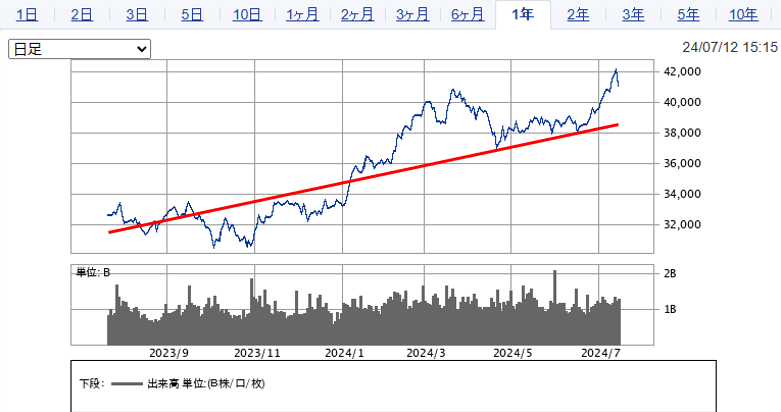
例えば、今から1年後には日経平均株価はいくらになっていることが予測できるでしょうか?赤線を見ると、右肩上がりなので44,000円くらいにはなっているのではないかという予想が立てられますよね。
この赤線のような線形(グラフ)を用いた、未来の数値の予測を線形回帰と呼びます。(赤線は何の計算もせず適当に書いた線ですが)
線形回帰も、単回帰分析と重回帰分析の2種類があります。
- 単回帰分析:上記の例では、時間が経つにつれて株価が上昇すると予測しています。このように、1つの変数のみを使った回帰分析の手法を単回帰分析と呼びます。
- 重回帰分析:株価は時間軸だけではなく、インフレ率や為替、消費動向などとも密接な関係があります。このように、複数の変数を使った回帰分析の手法を重回帰分析と呼びます。
次に、ロジスティック回帰ですが、過去のデータ(この場合は時間と株価)から何らかの法則を見つけ出すのは回帰分析と同じです。この見つけ出した法則を基に、1年後に日経平均株価が44,000円になる確率など、未来の事象の確率を予測するのがロジスティック回帰です。
“回帰”の由来
“回帰”に回帰感を感じないのは僕だけでしょうか?
なぜ回帰というのか気になって調べたところ、最初に回帰という現象を見出したゴルトンという学者がいたそうです。
ゴルトンは、祖先の身長の高い・低いに関わらず、子孫の身長は全人口の平均身長に回帰するという傾向を発見しました。この傾向を分析するための手法が統計学に受け継がれ、回帰分析と呼ばれるようになったそうです。
回帰の話は運営管理でもたまに出てくるので、単回帰分析と重回帰分析の違いくらいは押さえておきましょう!
教師なし学習
教師なし学習とは、教師あり学習とは異なり、正解(教師)が与えられていないデータを扱って学習させる手法です。
データを何かしらの観点に基づいて、グループ化(グルーピング)するのが特徴の手法です。正解がない状態の学習ですので、このグルーピングが教師なし学習を使う主な目的となります。
教師なし学習は、画像生成AIや異常検知システムなどに利用されています。
教師なし学習の代表的な手法としては、主成分分析やクラスター分析などがあります。
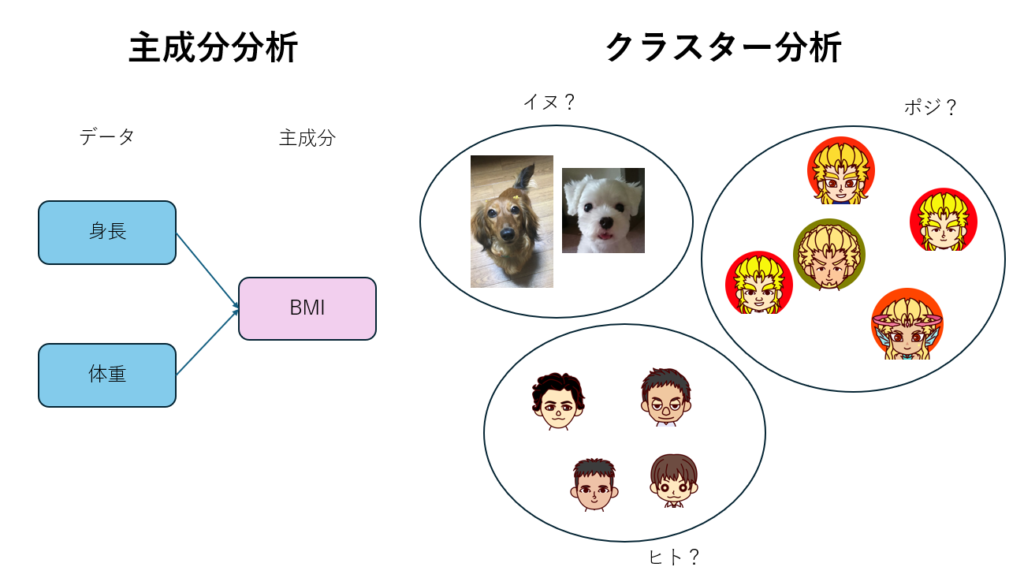
- 主成分分析:データの中から一定の法則を見つけ出す方法です。たくさんの変数の中を、より少ない変数にまとめます。例えば、肥満度を測る指標のBMIですが、身長と体重という2つの変数をBMIという1つの変数にまとめて、肥満度を算出しています。
- クラスター分析:クラスターとは、英語で「群れ」や「かたまり」を意味します(コロナ禍で一気に広まった言葉なので何となく知ってるかと思います)。大量のデータから、特徴の近いデータを集めてかたまりに分ける方法です。データが集まった集団をクラスターと呼び、クラスターを作ることをクラスタリングと呼びます。
強化学習
強化学習とは、一定の環境の中で試行錯誤を行い、個々の行動に対して得点や報酬を与えることによって、ゴールの達成に向けた行動の仕方を学習させる手法です。
例えば、二足歩行のロボットの場合、歩く速度や脚の曲げ方について試行錯誤を行い、長い距離を歩いた場合に報酬を与えるといったことを繰り返し、最終的には倒れずにスムーズな歩行ができることになります。
強化学習には、Q-Learning(Q学習)、SARSA、モンテカルロ法という3つの手法があります。
いずれの手法も、Q値と呼ばれる「ある状態sにおいてある行動aを取った時の報酬」を求めます。
- Q-Learning(Q学習):Q関数という行動報酬を計算する関数を用いる手法です。ある行動を行った場合の報酬はどれくらいであるかを計算して、一番得られる報酬が多いであろう行動を行い、その結果得られた報酬で行動の良し悪しを学習する手法です。
- SARSA:Q関数を使うのはQ-Learningと同じですが、SARSAの場合はQ関数に「ある行動を行った場合の価値 + 次の行動(方策)」も入れ込んで学習しています。今の状態(S)→今の行動(A)→得られた報酬(R)→次の状態(S)→次の行動(A)の5つの手順を組み込んでいるため、この頭文字を取ってSARSAと呼ばれています。これだけ見ると、SARSAはQ-Lerningの上位互換のような気がしますが、低速という大きなデメリットがあるため、Q-Learningの方がメジャーとなっています。
- モンテカルロ法:上記の2つの方法と違い、報酬の予測をせず、とにかく行動をして得られた報酬を基に、行動の良し悪しを学習します。
強化学習で一番有名なのは、Googleが開発した囲碁AIのAlphaGoでしょう。後述の深層学習と組み合わせた深層強化学習を行い、AlphaGo同士で対局を繰り返して学習を続け、囲碁のトッププロをも打ち破りました。
深層学習
深層学習とは、人間の脳の働きを模したディープニューラルネットワークを用いて学習させる手法です。
ニューラルネットワークは、入力層、 隠れ層 、出力層の 3 つの層から構成されており、特に隠れ層が複数あるニューラルネットワークを、ディープニューラルネットワークと呼んでいます。
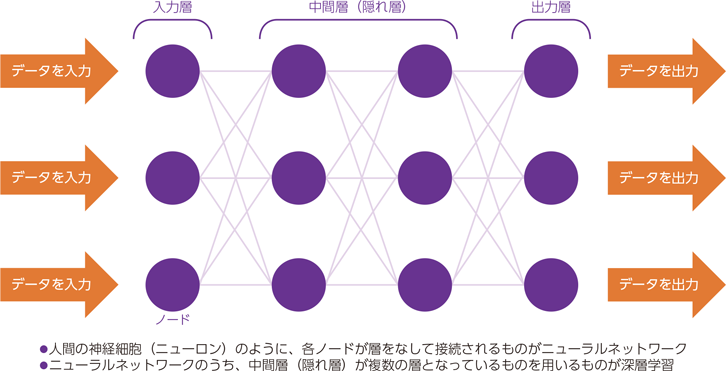
教師あり学習では、特徴量を人間が与えていましたが、深層学習は特徴量を機械が自分で見つけ出すのが大きな特徴です。
深層学習は自動運転や自動翻訳など、様々な分野で使われています。翻訳のDeepLや、画像生成のDALL-Eなどは有名なサービスで、利用されたことのある方も多いと思います。
おわりに
だいぶゴチャゴチャした解説となってしまったので、最後に令和元年度 情報通信白書に載っていたまとめを置いておきます。(てか最初からこれだけでよかったんじゃ・・・)

ちなみに僕は、この記事の執筆中にイヌやネコの特徴を調べまくったせいで、めちゃくちゃ動物を飼いたくなりました。

どちらかと言うとイヌ派だったけど、ネコもかわいいな。なんならウサギもアリだな。やっぱり飼うなら小型の動物のほうが狭い家でも飼えるしいいのかなぁ。でも大型の動物と暮らすのもロマンがあるよなぁ。別に今すぐ飼うわけじゃないし、将来的にちょっと都会から離れたところに住むとか?あ、多頭飼いできるし結構アリかも。でも、多頭飼いは難しそうだし、それとは別に何かあったときにお医者さんに診てもらうことを考えるとやっぱり都会の方が・・・
あ、明日はわたくしの記事ですので、よろしくお願いします・・・

☆☆☆☆☆
いいね!と思っていただけたらぜひ投票(クリック)をお願いします!
ブログを読んでいるみなさんが合格しますように。
にほんブログ村
にほんブログ村のランキングに参加しています。
(クリックしても個人が特定されることはありません)

